
带着问题去学习,是最有效的学习方法。所以按照惯例,我还是先给你出一个思考题:
问题一:为什么插入排序比冒泡排序更受欢迎?
如何分析一个“排序算法”?
最好情况、最坏情况、平均情况时间复杂度
时间复杂度的系数、常数、低阶
比较次数和交换次数
内存消耗
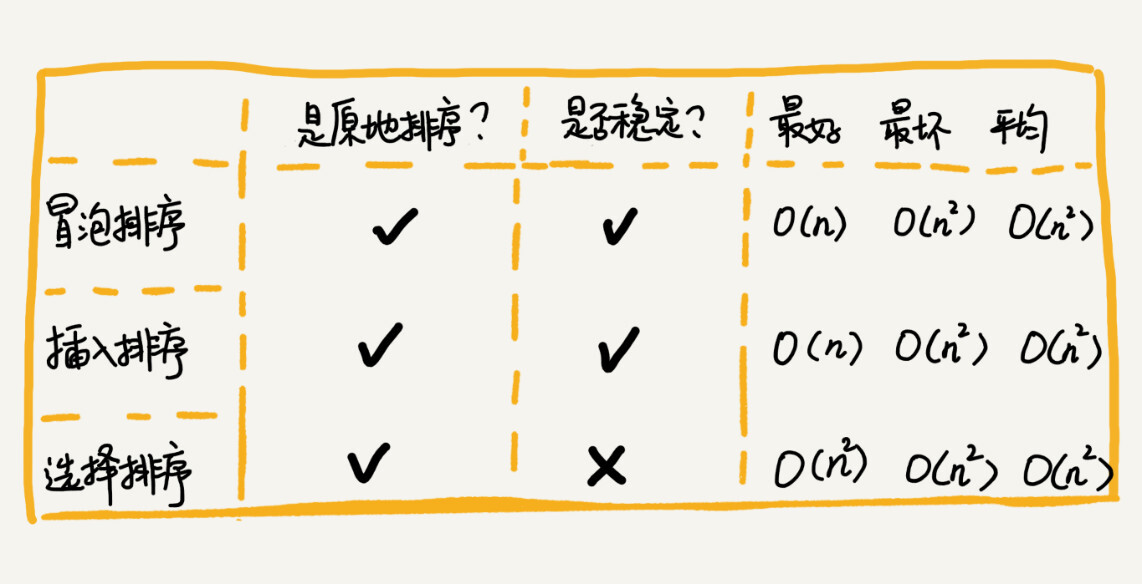
原地排序算法,就是特指空间复杂度是 O(1) 的排序算法。(冒泡排序、插入排序)
稳定性
- 经过某种排序算法排序之后,如果两个相同数值的前后顺序没有改变,那我们就把这种排序算法叫作稳定的排序算法;
- 如果前后顺序发生变化,那对应的排序算法就叫作不稳定的排序算法。
1、冒泡排序
- 冒泡排序只会操作相邻元素的两个数据
- 每次都是对相邻的两个元素比较大小,前面的元素大于后面的元素,交换前后元素,一轮循环后最后元素就是最大元素
- 第二轮循环后,倒数第二个元素就是第二大元素
- 直到所有元素都是有序的停止排序
冒泡排序图示:
1 | /// 冒泡排序 |
现在,结合刚才我分析排序算法的三个方面,我有三个问题要问你。
第一,冒泡排序是原地排序算法吗?
冒泡的过程只涉及相邻数据的交换操作,只需要常量级的临时空间,所以它的空间复杂度为 O(1),是一个原地排序算法。
第二,冒泡排序是稳定的排序算法吗?
在冒泡排序中,只有交换才可以改变两个元素的前后顺序。为了保证冒泡排序算法的稳定性,当有相邻的两个元素大小相等的时候,我们不做交换,相同大小的数据在排序前后不会改变顺序,所以冒泡排序是稳定的排序算法。
第三,冒泡排序的时间复杂度是多少?
最好情况下,要排序的数据已经是有序的了,我们只需要进行一次冒泡操作,就可以结束了,所以最好情况时间复杂度是 O(n)。而最坏的情况是,要排序的数据刚好是倒序排列的,我们需要进行 n 次冒泡操作,所以最坏情况时间复杂度为 O(n2)。平均时间复杂度也是O(n2)
2、插入排序
- 插入排序是将数组分成两个部分,已排序和未排序
- 初始化已排序部分只有一个元素就是数组第一个元素
- 插入排序的核心思想就是取出未排序部分的元素,在已排序区间中找到合适的插入位置插入,保证已排序区间的数据一直是有序的。
插入排序如下图:

1 | ///插入排序 |
插入排序也包含两种操作,一种是元素的比较,一种是元素的移动。当我们需要将一个数据 a 插入到已排序区间时,需要拿 a 与已排序区间的元素依次比较大小,找到合适的插入位置。找到插入点之后,我们还需要将插入点之后的元素顺序往后移动一位,这样才能腾出位置给元素 a 插入。
对于不同的查找插入点方法(从头到尾、从尾到头),元素的比较次数是有区别的。但对于一个给定的初始序列,移动操作的次数总是固定的,就等于逆序度 = 满有序度-初始有序度。
现在,结合刚才我分析排序算法的三个方面,我有三个问题要问你。
第一,插入排序是原地排序算法吗?
插入排序算法的运行并不需要额外的存储空间,所以空间复杂度是 O(1),也就是说,这是一个原地排序算法。
第二,插入排序是稳定的排序算法吗?
在插入排序中,对于值相同的元素,我们可以选择将后面出现的元素,插入到前面出现元素的后面,这样就可以保持原有的前后顺序不变,所以插入排序是稳定的排序算法。
第三,插入排序的时间复杂度是多少?
- 如果要排序的数据已经是有序的,我们并不需要搬移任何数据。如果我们从尾到头在有序数据组里面查找插入位置,每次只需要比较一个数据就能确定插入的位置。所以这种情况下,最好是时间复杂度为 O(n)。注意,这里是从尾到头遍历已经有序的数据。
- 如果数组是倒序的,每次插入都相当于在数组的第一个位置插入新的数据,所以需要移动大量的数据,所以最坏情况时间复杂度为 O(n2)。
- 还记得我们在数组中插入一个数据的平均时间复杂度是多少吗?没错,是 O(n)。所以,对于插入排序来说,每次插入操作都相当于在数组中插入一个数据,循环执行 n 次插入操作,所以平均时间复杂度为 O(n2)。
3、选择排序(Selection Sort)
选择排序算法的实现思路有点类似插入排序,也分已排序区间和未排序区间。但是选择排序每次会从未排序区间中找到最小的元素,将其放到已排序区间的末尾。
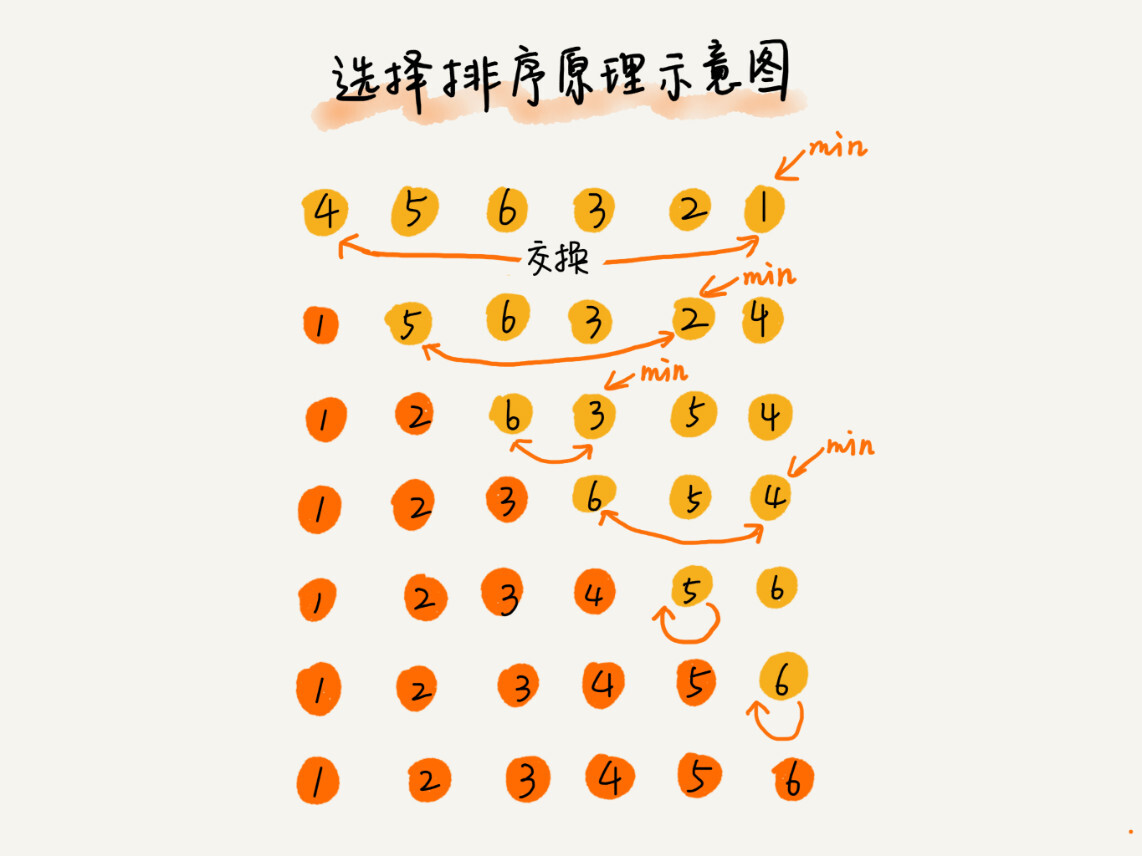
第一,选择排序是原地排序算法吗?
选择排序的时间复杂度是O(1)所以是原地排序
第二,选择排序是稳定的排序算法吗?
不是稳定排序,对于选择排序来说每次都是从未排序序列中找到最小的插入到已排序序列的末尾处,和前面的元素交换,这样会破坏稳定性
比如 5,8,5,2,9 这样一组数据,使用选择排序算法来排序的话,第一次找到最小元素 2,与第一个 5 交换位置,那第一个 5 和中间的 5 顺序就变了,所以就不稳定了。正是因此,相对于冒泡排序和插入排序,选择排序就稍微逊色了。\
第三,选择排序的时间复杂度是多少?
选择排序的最好情况时间复杂度、最坏情况和平均情况时间复杂度都为 O(n2)。
总结三种时间复杂度是 O(n2) 的排序算法
这三种排序算法,实现代码都非常简单,对于小规模数据的排序,用起来非常高效。但是在大规模数据排序的时候,这个时间复杂度还是稍微有点高,所以我们更倾向于用下一节要讲的时间复杂度为 O(nlogn) 的排序算法。
问题二:如何在 O(n) 的时间复杂度内查找一个无序数组中的第 K 大元素?
1、归并排序
归并排序的核心思想还是蛮简单的。如果要排序一个数组,我们先把数组从中间分成前后两部分,然后对前后两部分分别排序,再将排好序的两部分合并在一起,这样整个数组就都有序了。
归并排序的核心是合并:依次合并N个堆得数据
- 1、在合并时,您需要两个索引来跟踪两个数组的进度。
- 2、这是合并后的数组。 它现在是空的,但是你将在下面的步骤中通过添加其他数组中的元素构建它。
- 3、这个while循环将比较左侧和右侧的元素,并将它们添加到orderedPile,同时确保结果保持有序。
- 4、如果前一个while循环完成,则意味着leftPile或rightPile中的一个的内容已经完全合并到orderedPile中。此时,您不再需要进行比较。只需依次添加剩下一个数组的其余内容到orderedPile。
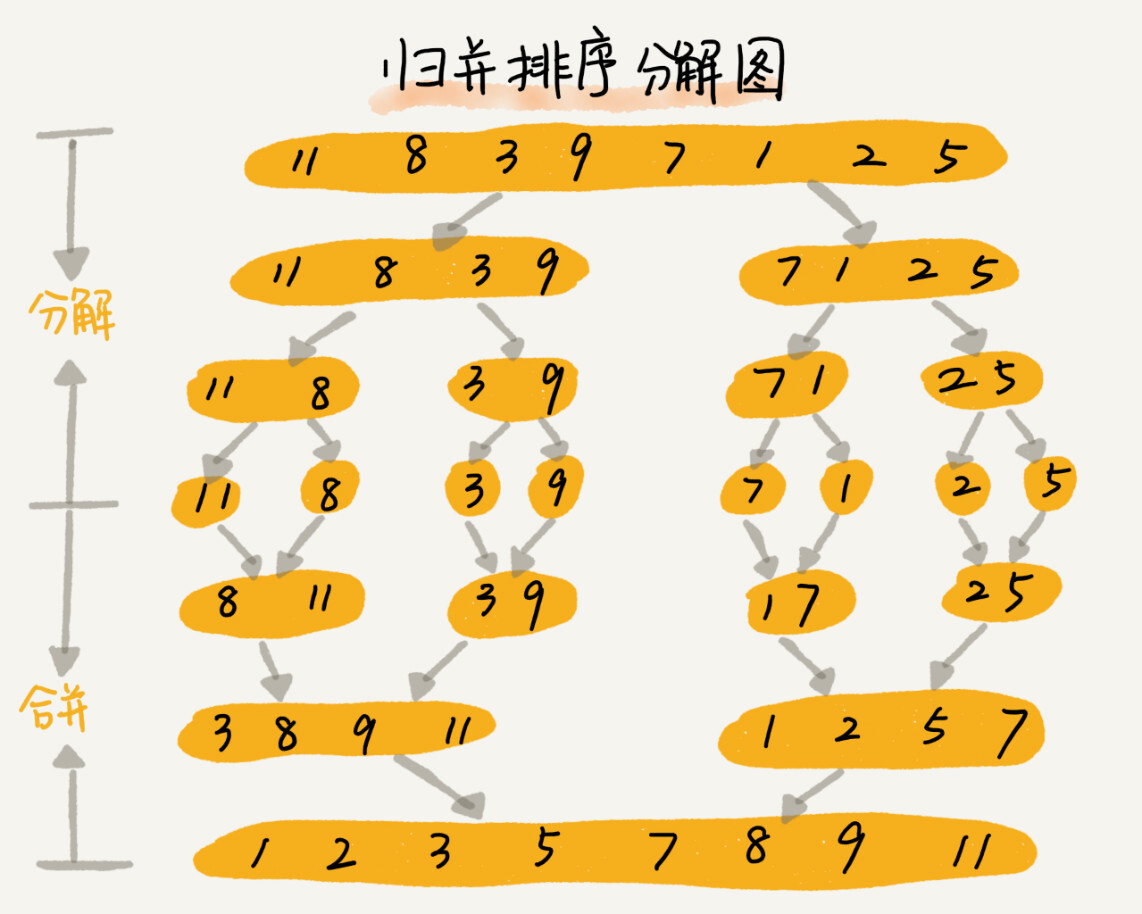
- 归并排序使用的就是分治思想。分治,顾名思义,就是分而治之,将一个大问题分解成小的子问题来解决。小的子问题解决了,大问题也就解决了。
- 从我刚才的描述,你有没有感觉到,分治思想跟我们前面讲的递归思想很像。是的,分治算法一般都是用递归来实现的。分治是一种解决问题的处理思想,递归是一种编程技巧,这两者并不冲突。
所以归并排序的核心就是递归写法:
1 |
|
有了递推公式,转化成代码就简单多了:
1 |
|
2、快速排序
归并排序虽然是稳定的、时间复杂度为 O(nlogn) 的排序算法,但是它是非原地排序算法。
归并之所以是非原地排序算法,主要原因是合并函数无法在原地执行。
快速排序通过设计巧妙的原地分区函数,可以实现原地排序,解决了归并排序占用太多内存的问题。
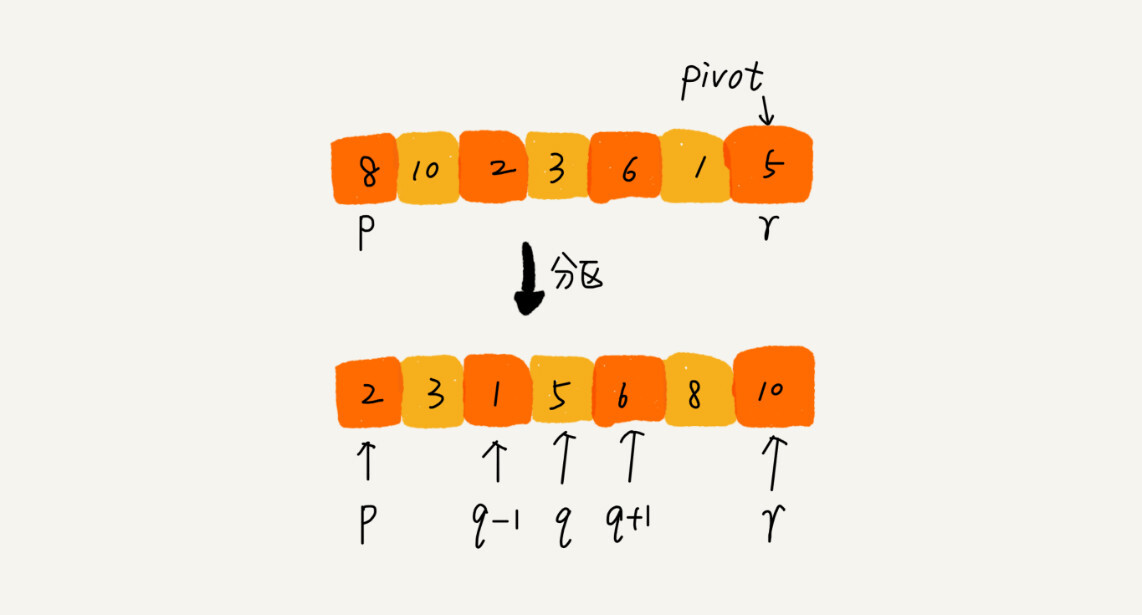
快排的思想是这样的:如果要排序数组中下标从 p 到 r 之间的一组数据,我们选择 p 到 r 之间的任意一个数据作为 pivot(分区点)。
我们遍历 p 到 r 之间的数据,将小于 pivot 的放到左边,将大于 pivot 的放到右边,将 pivot 放到中间。经过这一步骤之后,数组 p 到 r 之间的数据就被分成了三个部分,前面 p 到 q-1 之间都是小于 pivot 的,中间是 pivot,后面的 q+1 到 r 之间是大于 pivot 的。
直接递归:
1、设置中间位置元素为轴点元素pivot
2、分区:less equal more
3、递归合并分区
1 | func quickSort<T: Comparable>(_ array: [T]) -> [T]{ |
Lomuto分区 Vs Hoare分区 Vs 荷兰国旗分区
Lomuto分区法:是用数组最后一个元素作为基准元素对数组分区,区域为[low…p-1] [p+1…high],然后递归调用quickLomutoSort分别对左右区排序,一直到数组有序
Hoare分区:选择数组的first元素作为基准,数组划分区域为[low…p] [p+1…high],然后递归调用quickSortHoare分别对左右区排序,一直到数组有序
1 | /* |
解答问题二:
快排核心思想就是分治和分区,我们可以利用分区的思想,来解答开这个问题:O(n) 时间复杂度内求无序数组中的第 K 大元素。比如,4, 2, 5, 12, 3 这样一组数据,第 3 大元素就是 4。
我们选择数组区间 A[0…n-1]的最后一个元素 A[n-1]作为 pivot,对数组 A[0…n-1]原地分区,这样数组就分成了三部分,A[0…p-1]、A[p]、A[p+1…n-1]。
如果 p+1=K,那 A[p]就是要求解的元素;如果 K>p+1, 说明第 K 大元素出现在 A[p+1…n-1]区间,我们再按照上面的思路递归地在 A[p+1…n-1]这个区间内查找。同理,如果 K<p+1,那我们就在 A[0…p-1]区间查找。
本文参考:王争-数据结构与算法之美